| 2766-6863 | |
| 2766-6863 (service hours) | |
| Online Form | |
| Contact your Faculty Librarians on in-depth research questions |

Image CC-BY-SA by SangyaPundir
What is FAIR Data
To make your shared data useful, your data should be as FAIR as possible. FAIR stands for Findable, Accessible, Interoperable, and Reusable. It is a set of guiding principles formulated by Force11, aiming at optimizing discovery and reuse of research data.
FAIR data is a framework for you to manage your research data to be shared so that other researchers will be able to find it, understand it, and reuse it effectively. Below is a simplified description of what is FAIR. We encourage you to read the original document for details.
► Findable
Make sure the data is discoverable by the others with rich metadata and assigned with a persistent identifier, e.g. a DOI.
► Accessible
Both data and metadata should be retrievable via a standard protocol. In case the data cannot be made open, do make sure to keep the metadata publicly available.
► Interoperable
(Meta)data should be interpretable with different tools, applications, and systems by using recognized formats and standards.
► Reusable
There should be a clear license for the reuse of shared data, and with proper documentation in order to help others to interpret and reuse it.
Depositing your research data in a data repository is a good way to help your data to be FAIR, as these data repositories usually will assign a DOI to your data, populate the metadata, and assist you to specify the reuse license of your data.
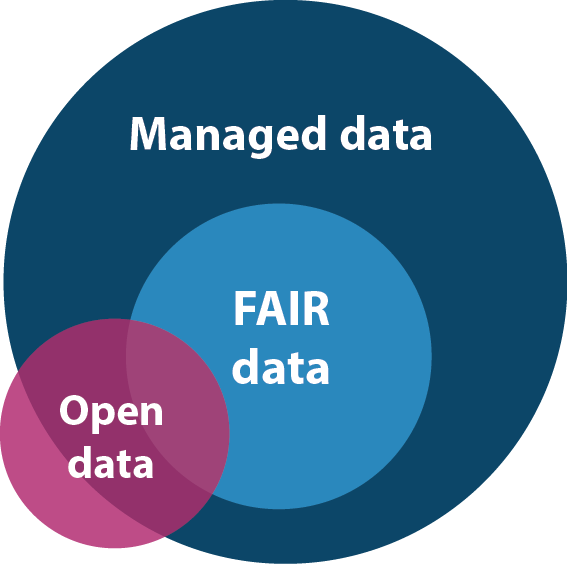
Does open data equal to FAIR data
While data can be made open, it may not always be FAIR.
Open data allows everyone to access, use, and share without restrictions arising from licenses, copyright, and patents. However, we need to do more if we wish people to be able to benefit from our shared data. For example, assigning persistent identifiers, such as DOI, to our data, providing proper metadata, presenting the data in a standardized way, and stating the conditions to reuse the data. To maximize the value of the shared data, data need to be FAIR.
On the other hand, FAIR data does not mean they have to be made open. Restrictions can be adopted when it involves commercial interest, personal privacy, national security, and public interest. In these cases, the metadata of the data will still be publicly available, with information about the conditions for accessing the data.
As data must be well managed before it can be FAIR and effectively shared, it is encouraged to plan at the beginning of your research project if you wish or are required to share the research data.
You may watch this 5-minute video which explains why well-managed data is necessary for effective data sharing.