| 2766-6863 | |
| 2766-6863 (service hours) | |
| Online Form | |
| Contact your Faculty Librarians on in-depth research questions |

Data Documentation & Metadata
Data documentations are human-readable files and records explaining the content, structure, and meaning of data; while metadata are standardized, machine-readable fields that make the data discoverable and reusable.
They both provide information about the data, ensure your data is understandable, make future analysis and reuse possible, and thus increase the value of your research data.
It is always easier to create data documentation at the beginning of your research project and update it throughout the research process. Good data documentation usually explains at:
Depending on the nature of the research and data collection method, data documentation can be recorded in different forms like read-me file, data dictionary, codebook, laboratory notebook, dairy, etc. They all share the same goals - to ensure your research data can be understood by current and future researchers who would like to make use of the data again, including yourself!
Metadata means data about data. It provides a structured way to describe the datasets in a standardized manner. This allows different computers to interpret the contents automatically which facilitates interoperability among different systems. Below are the common elements of metadata:
| Types | Functions |
Examples |
 Descriptive Metadata |
Enables discovery, indexing, and retrieval. |
|
 Technical Metadata |
Describes how a dataset was produced and structured. |
|
 Administrative Metadata |
Describes user rights and management of the dataset. |
|
Metadata Standards
Metadata can be recorded in a variety of formats like text documents, HTML, or XML. An example of a widely used metadata standard for generic research data is Dublin Core (DC). You can also make use of the following tools to identify the common metadata standards used in your subject areas:
A readme file provides information about a data file. It helps ensure other researchers and yourself can understand and reuse the data in the future. A typical readme file is usually saved in a plain text file rather than in proprietary formats (e.g. MS Word) for long-term accessibility.
You can learn how to create a readme file from Cornell University’s Research Data Management Service Group, and download their suggested template to adapt it for your own data.

A data dictionary is a file that provides meaningful descriptions for each variable and value of your dataset. Below is an example from the Open Science Framework (OSF). Learn more from its section on How to Make a Data Dictionary.
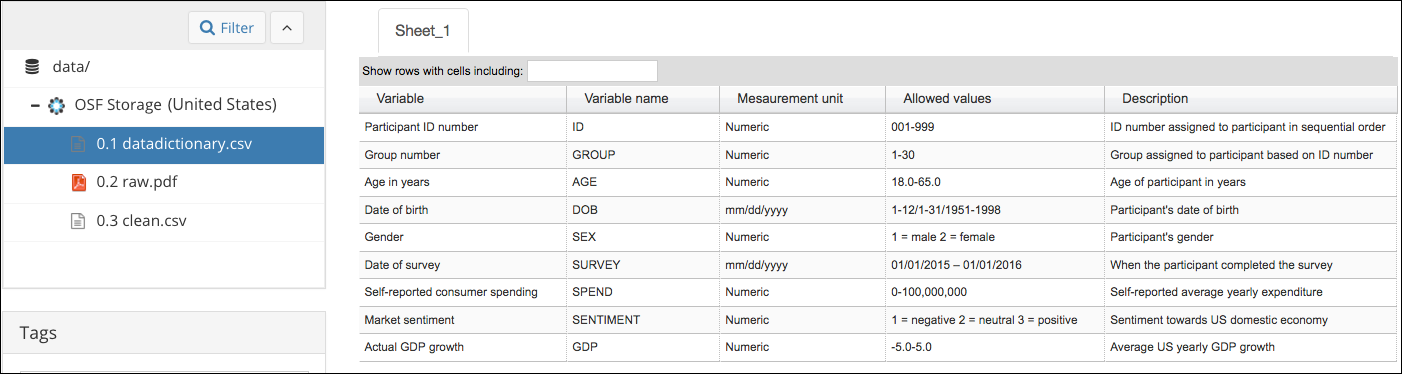
For data including Python or R scripts, you may also provide brief information and the purpose of the code.
A codebook provides information about data from a survey instrument. It describes the contents, structure, and layout of the data file, the response codes that are used to record survey responses, and other information.
Below is an example from the ICPSR Guide to Codebooks. We recommend you read the guide from ICPSR for more details.


Laboratory notebook documents the inputs, conditions, workflows, and other information in conducting an experiment. It records data provenance, and thus improves the transparency of the research process as well as increases the reliability of research results.
A lot of researchers are now using Electronic laboratory notebooks (ELNs) to replace the traditional paper laboratory notebooks because it: